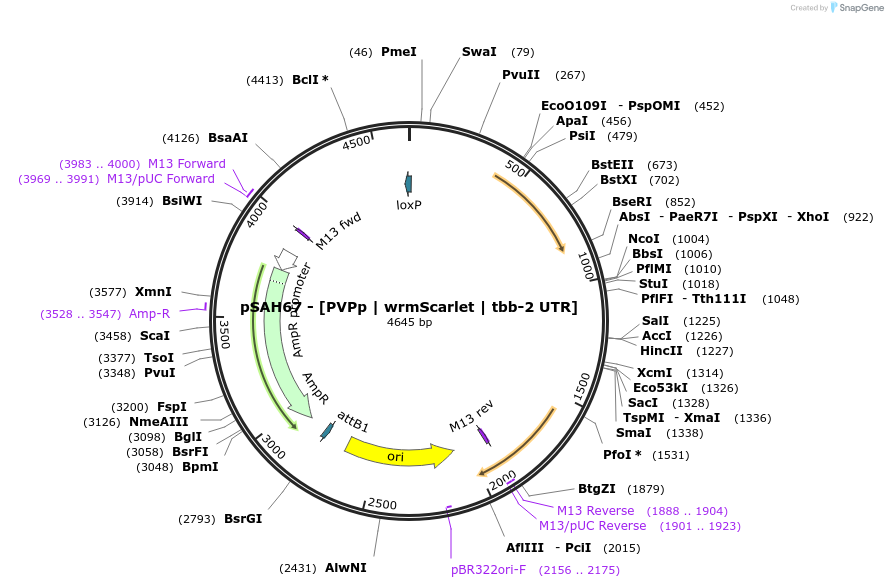
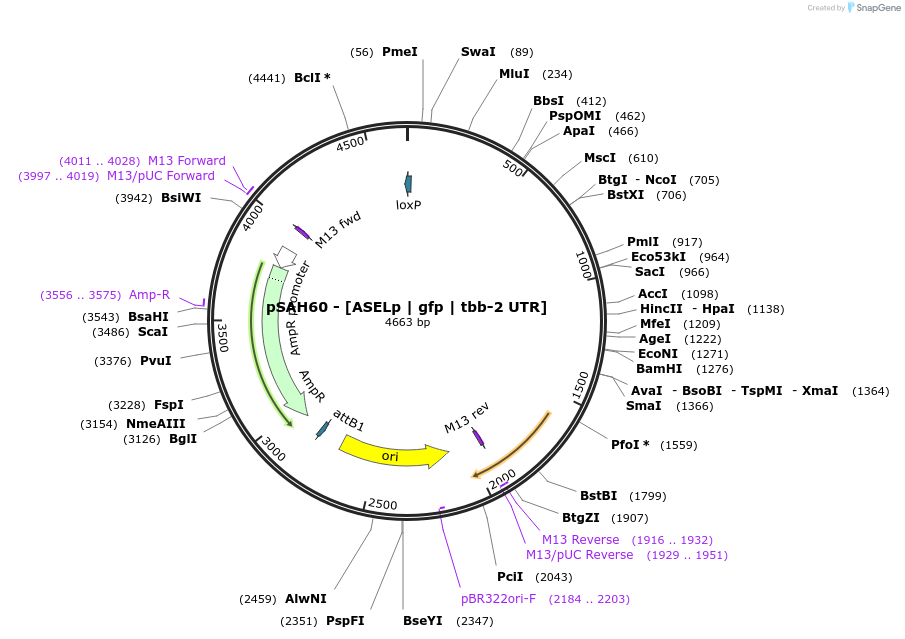
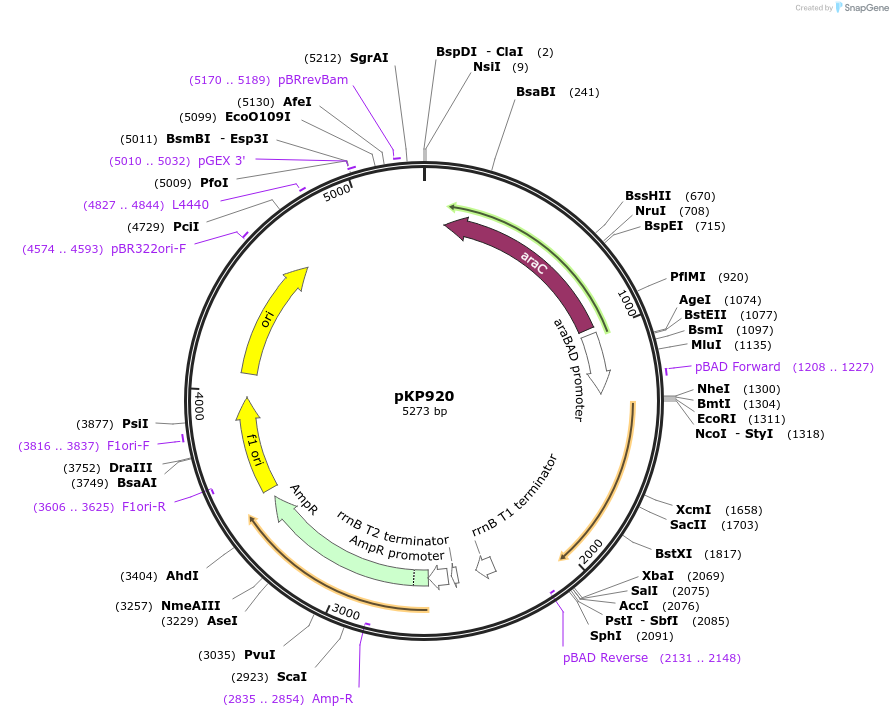
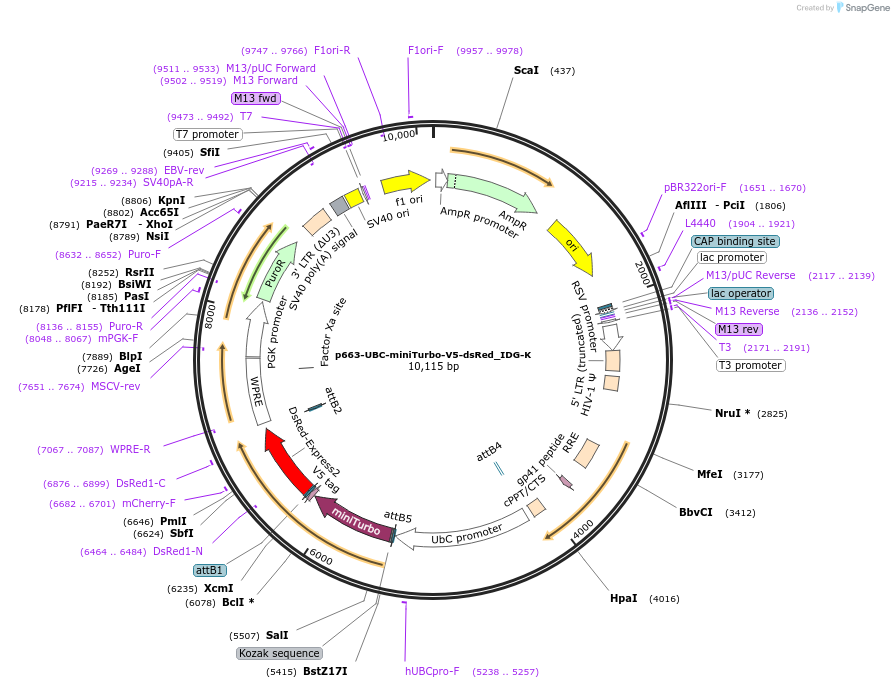
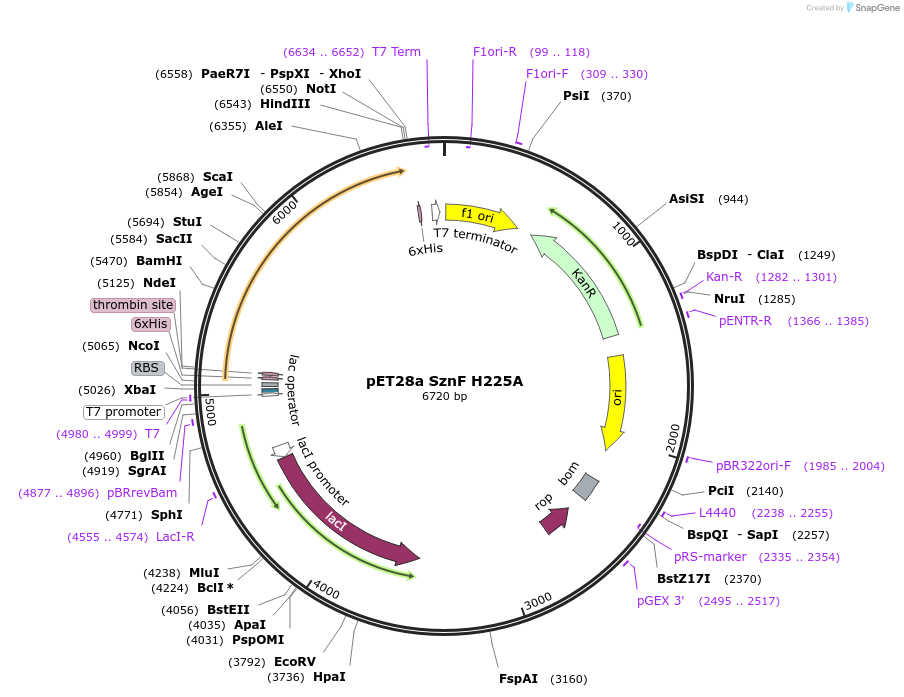
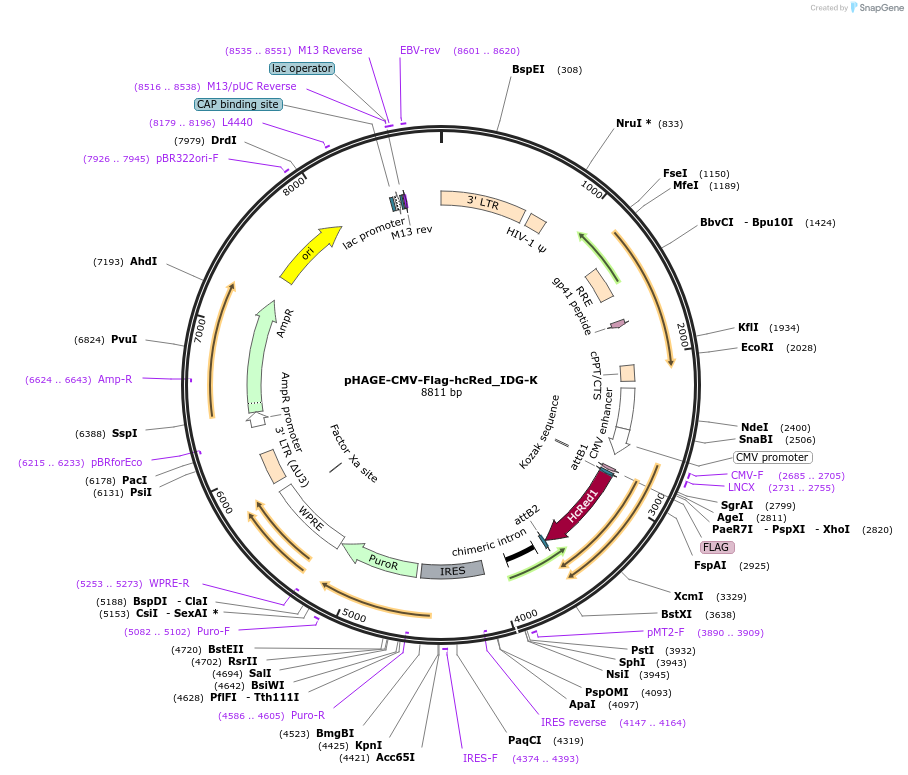
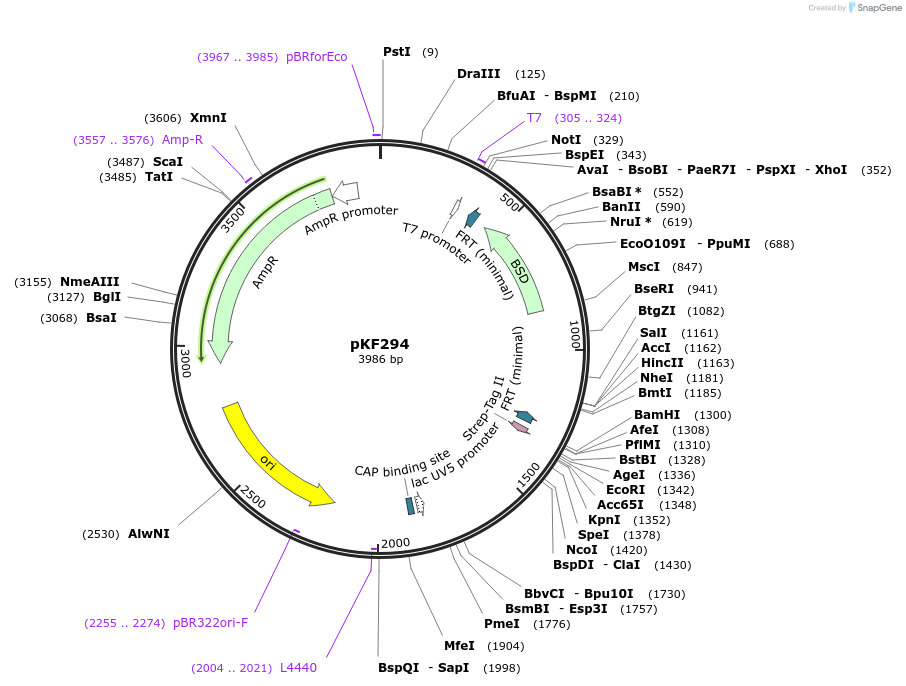
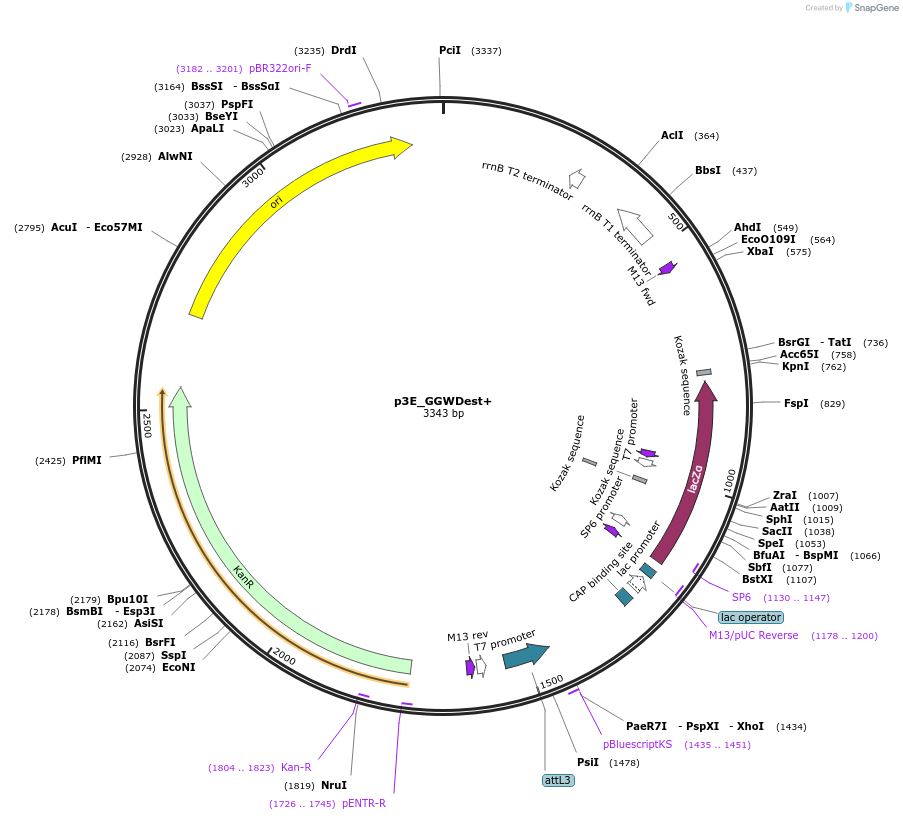
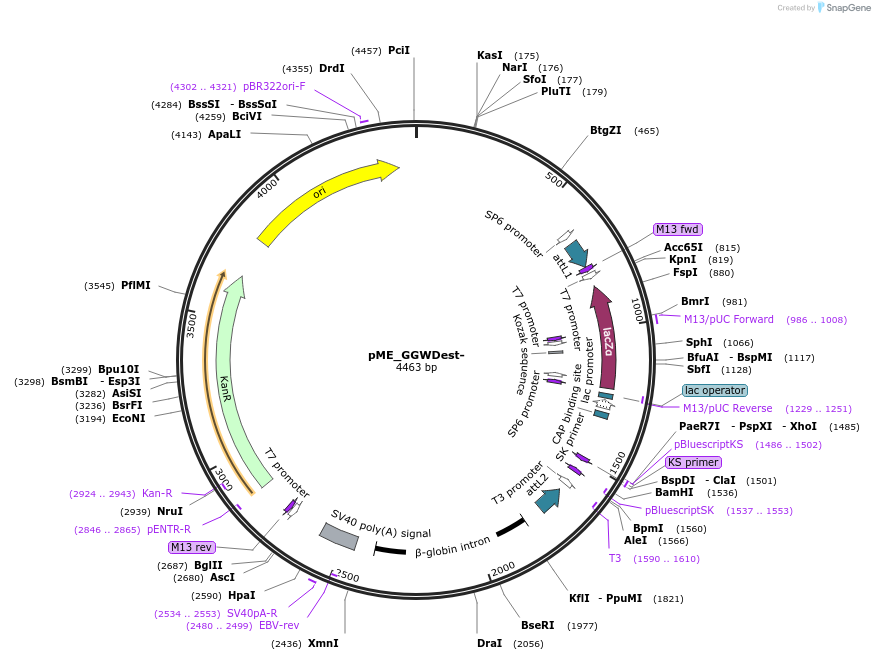
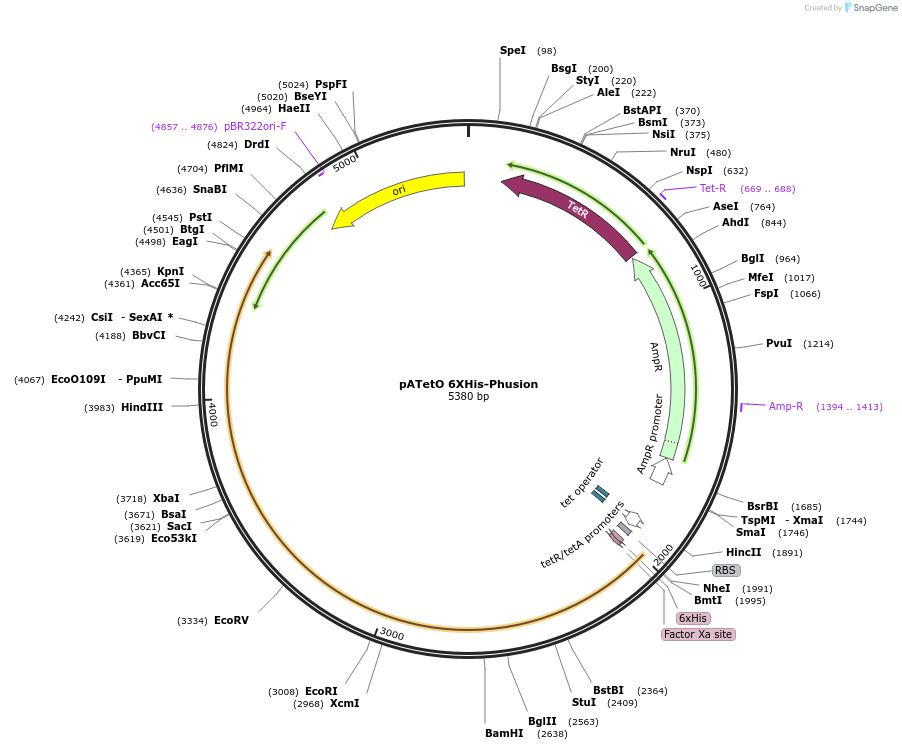
pSAH67 - [PVPp | wrmScarlet | tbb-2 UTR]
Plasmid
#200341
Purpose
mScarlet BioPart for PVP neurons. (1) Mark neurons or (2) cell-specific expression of transgenes (N or C-terminal fusions, or untagged). Compatible with single-copy insertion (MosTI) or arrays.
Depositor
Insert
[PVPp | wrmScarlet | tbb-2 UTR]
Expression
Worm
Promoter
WBGene00003840, ocr-3
Available Since
June 15, 2023
Availability
Academic Institutions and Nonprofits only